JavaScript
条评论== 和 ===
- ==:比较值,类型不同的时候,先进行类型转换,再比较值;1 == “1” true
- ===:比较类型和值,不做类型转换,类型不同就是不等;1 === “1” false
[] == false,是true还是false,隐式转换
true。
- NaN和其他任何类型比较永远返回false。
- Boolean 和其他任何类型比较,Boolean 首先被转换为 Number 类型。
- String和Number比较,先将String转换为Number类型。
- null == undefined比较结果是true,除此之外,null、undefined和其他任何结果的比较值都为false。
- 两个引用类型比较,引用地址不一样,直接false。
- 原始类型和引用类型做比较时,引用类型会依照ToPrimitive规则转换为原始类型。
- 引用类型先调用valueOf(),如果是基本类型,直接返回
- 不是基本类型,再调用toString
- String再转Number
与或非优先级运算
与或非混合时,非>与>或。
1
2true && !false || false // true
false || !false && false // false&& 和 || 的短路运算
&&的短路运算:左边能转成false,无条件返回左边式子的值。反之无条件返回右边式子的值
1
2false && 1; // 输出false
true && 1; // 输出1||的短路运算:若左边能转成true,无条件返回左边式子的值。反之无条件返回右边式子的值
1
2false || 1; // 输出1
true || 1; // 输出true
Object.is(value1, value2)
Object.is()是在ES6中定义的一个新方法,它与‘===’相比,特别针对-0、+0、NaN做了处理。1
2
3
4
5+0 === -0 // true
NaN === NaN // false
Object.is(+0, -0) // false
Object.is(NaN, NaN) // true
Object.is(NaN, 0/0) // true
6种基本数据类型和3种引用类型
- number, boolean, string, null, undefined, Symbol
- Object, Array, Function
javascript自带的数据结构
- Object, Array, Set, Map, WeakSet, WeakMap
null和undefined有什么区别
- null表示空对象
- undefined表示未初始化的变量
number的最大/小值,最大/小安全整数,位数
Number.MAX_VALUE,Number.MIN_VALUE,Number.MAX_SAFE_INTEGER,Number.MIN_SAFE_INTEGER
所有 JavaScript 数字均为 64 位。其中 0 到 51 存储数字(占52位),52 到 62 存储指数(占11位),63 位存储符号。
Object 和 Map 有什么区别
- Object 键(key)的类型只能是字符串,数字或者 Symbol;而 Map 可以是任何类型。
- Map 中的元素会保持其插入时的顺序;而 Object 则不会完全保持插入时的顺序。
- Object的key顺序:
- key是整数或者整数类型的字符串,那么会按照从小到大的排序。
- 其它数据类型,控制台展示的时候,按照ASC码升序排序,如果用Object.keys()获取,按照实际创建顺序排序。
- Map 是可迭代对象,所以其中的键值对是可以通过 for of 循环或 .foreach() 方法来迭代的;而普通的对象键值对则默认是不可迭代的,只能通过 for in 循环来访问。
一个对象作为key,会自动转成[object,Object],第二个O大写
1 | var a = { name: "Sam" }; |
function.length可以获取函数的参数个数
1 | const sum = (a, b, c) => a + b + c |
函数柯里化
柯里化是编程语言中的一个通用的概念(不只是Js,其他很多语言也有柯里化),是指把接收多个参数的函数变换成接收单一参数的函数,嵌套返回直到所有参数都被使用并返回最终结果。
更简单地说,柯里化是一个函数变换的过程,是将函数从调用方式:f(a,b,c)变换成调用方式:f(a)(b)(c)的过程。
柯里化不会调用函数,它只是对函数进行转换。
1 | const sum = (a, b, c) => a + b + c |
基本数据类型和引用类型存储在哪里
- 基本数据类型:变量标识符和变量的值存放于栈内存。占用固定大小的空间。
- 引用类型:变量标识符和指向堆内存中该对象的指针存放于栈,具体的对象存放于堆。
一个string,他不定长,放在栈中是怎么处理的?
基本数据类型不一定是直接存在栈中的。
- 字符串: 存在堆里,栈中为引用地址,如果存在相同字符串,则引用地址相同。
- 数字: 小整数(-2³¹ 到 2³¹-1(2³¹≈2*10⁹)的整数)存在栈中,其他类型存在堆中,如小数。
- 其他类型:引擎初始化时分配唯一地址,栈中的变量存的是唯一的引用。
函数的参数是按照什么方式传递的
按值传递 vs 按引用传递
- 按值传递:实际参数把它的值传递给对应的形式参数,形式参数只是用实际参数的值初始化自己的存储单元内容,是两个不同的存储单元,所以方法执行中形式参数值的改变不影响实际参数的值。按值传递的意思就是形参是实参的复制。
- 按引用传递:就是传递对象的引用,实参和形参是完全一样的,函数内部对形参的任何改变都会影响实际参数。函数的形参接收实参的隐式引用,而不再是副本。
首先理解复制变量:
- 基本数据类型:将原始值副本赋值给新的变量,所以两个变量是完全独立的,只不过value相同。
- 复杂类型:将指针(内存地址)赋值给新的变量,所以两个变量保存的内存地址一致,也就是指向的具体的对象一致。任何一个改变都会影响另一个。
传递参数
传递参数就是变量复制的过程,将实参的值赋值给形参。
其实都是按值传递的。只不过有的值是基本类型,有的值是内存地址
证明不是按引用传递
1 | var person = { name: "MJ" }; |
说明形参obj和实参person是两个东西,只不过值相同,都是同一个内存地址,都指向了同一个对象。
如果是按引用传递,那他两个应该是同一个东西,修改obj=new Object()之后,person也应该是这个新的object。
js内置对象
基本对象:
- Object
- Function
- Array
- Number
- String
- Boolean
其他对象:
- Error
- Date
- Math
- RegExp
- JSON
ES6新增对象:
- Symbol
- Set & WeakSet
- Map & WeakMap
- Proxy
- Reflect
- Promise
闭包
一个函数包含另一个函数,并且被包含的函数使用了父函数中的变量。内部函数即为闭包。
即有权访问另一个函数作用域内变量的函数都是闭包。
闭包的特性:
内部函数总是可以访问其所在的外部函数中声明的参数和变量,即使在其外部函数被返回(寿命终结)了之后闭包的作用:
- 使其他函数可以访问某函数内部的变量
- 让函数内部的变量一直隐藏/保存在内存中(但是这样会导致内存泄漏,所以在退出函数之前,应将不使用的局部变量设为null)
- 实现私有变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function Person(){
var name = 'cxk';
this.getName = function(){
return name;
}
this.setName = function(value){
name = value;
}
}
const cxk = new Person()
console.log(cxk.getName()) //cxk
cxk.setName('jntm')
console.log(cxk.getName()) //jntm
console.log(name) //name is not defined
// 函数体内的var name = 'cxk'只有getName和setName两个函数可以访问,外部无法访问,相对于将变量私有化
立即执行函数(IIFE)
1 | (function(j){ |
作用:
- 创建一个独立的作用域。这个作用域里面的变量,外面访问不到(即避免「变量污染」)
- 如果需要访问这里面的方法,可以挂载在window上,或者return给外面。以此模拟模块。
js运行机制
JavaScript代码的整个执行过程,分为两个阶段,代码编译阶段与代码执行阶段。
编译阶段
- 词法分析(Tokenizing/Lexing)
- 语法分析(Parsing)
- 预编译(解释)
执行阶段
将JavaScript代码分为一块块的可执行代码块进行执行,在代码块执行前会创建执行上下文,目前有三类代码块:
- 全局代码块(Global code)
- 函数代码块(Function code)
- eval代码块(Eval code)
执行上下文
根据这三类代码快创建三种执行上下文
- 全局执行上下文
- 函数执行上下文
- eval执行上下文
执行上下文也分为两个阶段(ES6规范):
- 创建阶段
- 决定 this 的指向
- 创建词法环境(LexicalEnvironment) (也就是作用域)
- 函数声明
- 变量声明
- 确立作用域和作用域链
- 创建变量环境(VariableEnvironment)
- var类型的变量声明(变量提升)
- 执行阶段
- 变量赋值
- 函数执行
函数调用栈
代码在运行过程中,会有一个叫做调用栈(call stack)的概念。调用栈是一种栈结构,它用来存储计算机程序执行时候其活跃子程序的信息(即执行上下文)。
在执行阶段,先将全局执行上下文放入函数调用栈栈底,然后执行函数,并将函数执行上下文放入栈。
处于栈顶的上下文执行完毕之后,就会自动出栈。函数中,遇到return能直接终止可执行代码的执行,因此会直接将当前上下文弹出栈。
作用域,作用域链
在ES6规范中,作用域更官方的叫法是词法环境(Lexical Environments),它由两部分组成:
- 记录作用域内变量信息(我们假设let变量,const常量,函数等统称为变量)和代码结构信息的东西,称之为 Environment Record。
- 一个引用
__outer__,这个引用指向当前作用域的父作用域。全局作用域的__outer__为 null。
可执行上下文中的词法环境中含有外部词法环境的引用,我们可以通过这个引用获取外部词法环境的变量、声明等,这些引用串联起来一直指向全局的词法环境,因此形成了作用域链。
变量查找(ResolveBinding):
先从当前的执行上下文中找保存的作用域,查看当前作用域里面的 Environment Record 是否有此变量的信息,如果找到了,则返回当前作用域内的这个变量。如果没有查找到,则顺着 __outer__ 到父作用域里面的 Environment Record 查找,以此递归。
变量提升
在执行上下文的创建阶段,会先声明var类型的变量,但不进行赋值,执行阶段才去赋值。
所以在后面的代码中可以先使用这个变量,但是他是undefined
var变量声明 和 函数声明都会变量提升
- var变量声明 和 函数声明都会变量提升
- 函数声明是整体提升,优先级高于var声明,且直接赋值
- 具体的执行是什么取决于赋值是什么。
1
2
3
4
5
6
7
8
9var log = function () {
console.log(1)
};
function log() {
console.log(2)
}
log() // 输出 1
// function log 先提升, var log 再提升,function log 会直接给log 赋值。 var log = function 再赋值,所以最后log是consolo.log(1)的
this指向
简单来说,谁调用这个函数,这个函数中的this就指向谁
fn()fn单独调用,this指向windowobj1.obj2.fn();this指向obj2var bar = obj.fn; bar();this指向window- call()、apply()、bind(),指向新的这个对象
- 箭头函数中this指向所在上下文
从原理上来说,在创建可执行上下文的时候,根据代码的执行条件,来判断分别进行默认绑定、隐式绑定、显示绑定等。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15var x = 0;
var obj = {
x: 10,
bar() {
var x = 20;
console.log(this.x);
}
}
obj.bar() // 10
var foo = obj.bar;
foo() // 0
obj.bar.call(window) // 0
obj.bar.call(obj) // 10
foo.call(obj) // 10
v8执行原理
- 初始化堆栈空间,全局上下文,全局作用域,事件循环系统。
- 输入全局的js代码,解析器(Parser)通过词法分析,生成tokens,语法分析根据tokens生成AST抽象语法树。
- 解释器(Ignition) 会将 AST 转换为字节码,一边解释一边执行。(解释执行)
- 在解释执行字节码的过程中,如果发现一段代码被多次重复执行,就会将其标记为热点(Hot)代码。V8 会将这段热点代码丢给优化编译器 TurboFan 编译为二进制代码。如果下次再执行时,就会直接执行二进制代码,提高执行速度。(编译执行)
- 如果遇到普通函数,只会对其进行预解析(Pre-Parser),验证函数的语法是否有效、解析函数声明以及确定函数作用域,并不会生成 AST,当函数被调用时,才会对其完全解析。
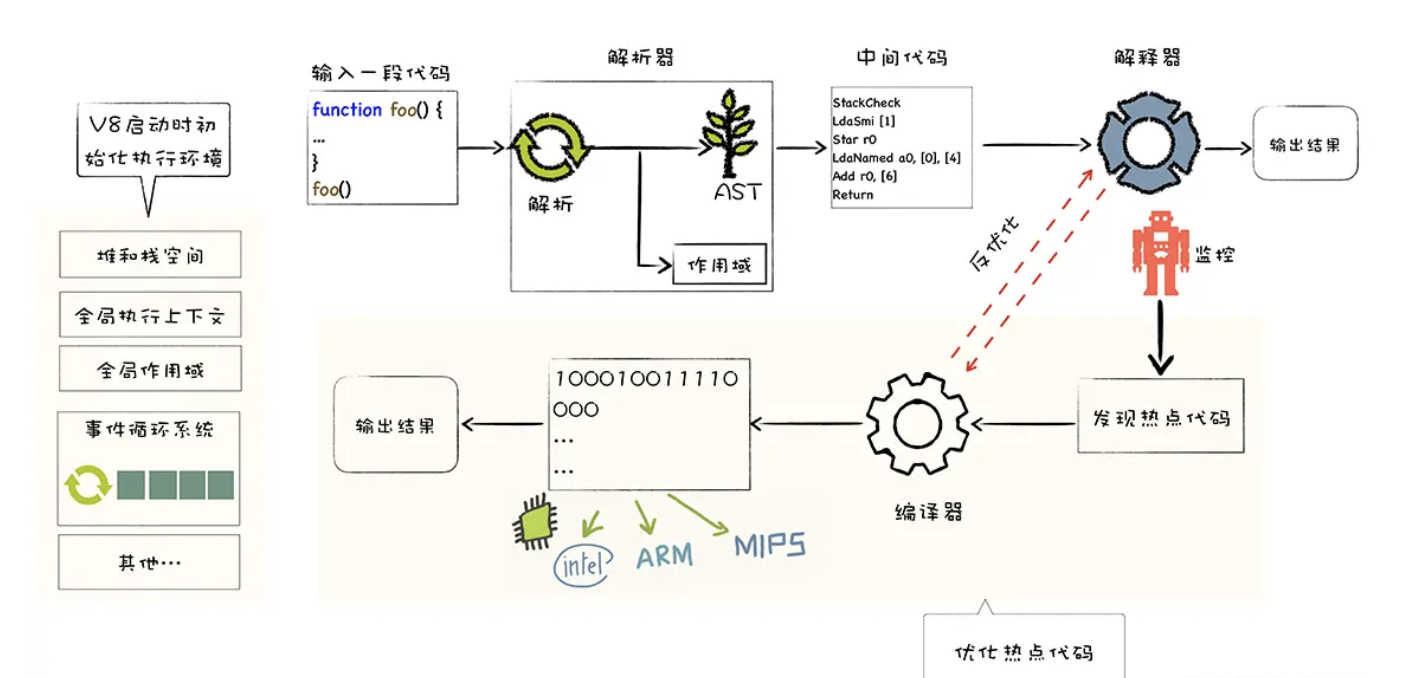
js 到底是解释型还是编译型语言?
V8 同时采用了解释执行和编译执行这两种方式,这种混合使用的方式称为 JIT (即时编译)。
什么是作用域链,什么是原型链,它们的区别
- 作用域是针对变量的,先在自己的作用域上下文寻找, 找不到再去父级作用域寻找,形成作用域链。
- 原型链是针对对象属性或者方法的, 当我们从一个对象上寻找某个属性或者方法时, 先在本身寻找, 没有的话就去父类的原型上找。父类原型找不到,再去父类的父类的原型找。形成原型链。
原型,原型链,构造函数
原型:即prototype属性,只有函数才有,用来存放所有实例对象需要共享的属性和方法。那些不需要共享的属性和方法,就放在构造函数里面。
构造函数:用来创建实例。通过new关键字可以创建实例。命名通常首字母大写。
原型链:即proto属性,任何对象都有这个属性。
结论:
- 对象的proto属性指向父类的prototype属性,没有父类则指向Object.prototype
- 类的proto属性指向父类,如果没有父类指向Function.prototype。ES5中用function创建的类,proto都指向Function.prototype。
- 对象的.constructor指向本类
- 类的prototype.constructor指向本类
- 类的.constructor指向Function
- 类的prototype是父类的实例, 所以instanceof 父类是true,没有父类时instanceof Object是true
5.6 也证明在自己写继承的时候, 要些这两行代码。1
2Son.prototype = new Father();
Son.prototype.constructor = Son;
当我们访问一个对象的属性或方法时,如果这个对象内部不存在这个属性,那么他就会去他的proto里找这个属性,也就是去父类的protorype上找,父类的prototype上如果没有,这个prototype又会去找他的proto,这个proto又会有自己的proto,于是就这样 一直找下去,也就是我们平时所说的原型链的概念。
一张图总结:主要是每个部分都要明白 proto 和 constructor的指向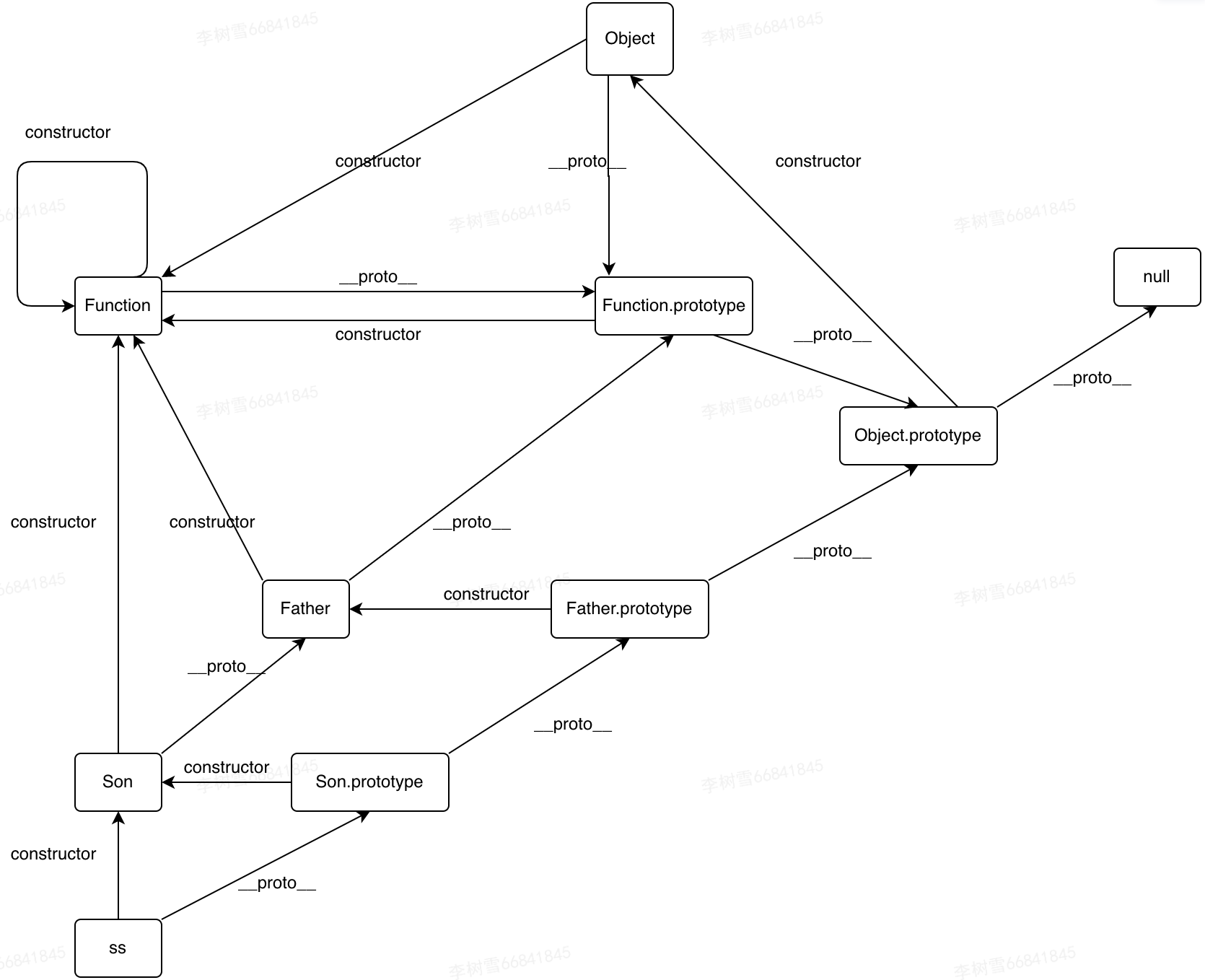
1 | class GrandPa { |
ES5继承
1 | // 组合继承 |
new 操作符做了什么?怎么模拟new ?
- 创建了一个空对象
var obj = {} - 将对象的proto指向函数的prototype
obj.__proto__ = Constructor.prototype - 将函数的this绑定到这个空对象上
var result = Constructor.apply(obj, arguments) - 判断构造函数的返回值类型,如果没有返回值或者返回值是值类型,返回obj这个新创建的实例(相当于this)。如果返回值时是引用类型比如return {x: ‘a’},就返回这个引用类型的对象。
return result instanceof Object ? result : obj
模拟实现new1
2
3
4
5
6function new2(Constructor, ...args) {
var obj = {};
obj.__proto__ = Constructor.prototype; // 或者Object.setPrototypeOf(obj, Constructor.prototype)
var result = Constructor.apply(obj, args);
return result instanceof Object ? result : obj
}
箭头函数可以作为构造函数吗?
不可以。
普通函数在运行时才会确定 this 的指向。箭头函数则是在函数定义的时候就确定了 this 的指向,此时的 this 指向外层的作用域。所以不可以用来做构造函数,因为如果做构造函数,生成的实例的this不是指向实例,而是指向箭头函数的上下文,这是不对的。
obj.hasOwnProperty(prop)
hasOwnProperty() 方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性,忽略那些从原型链上继承到的属性。
typeof, instanceof, Object.prototype.toString.call()
typeof 可以用于判断基本数据类型和函数,判断不出来null对象数组和实例。输出的是小写的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17typeof 1 // "number"
typeof '1' // "string"
typeof true //"boolean"
typeof undefined // "undefined"
let s = Symbol()
typeof s // "symbol"
typeof function(){} // "function"
typeof Object // "function"
typeof Array // "function"
typeof Function // "function"
typeof null // "object"
typeof {} // "object"
typeof [] // "object"
typeof new Boolean(false) // "object"
typeof new Date() // "object"Object.prototype.toString.call(),可以精确判断所有类型
1
2
3
4
5
6
7
8
9
10
11Object.prototype.toString.call(1) // "[object Number]"
Object.prototype.toString.call('1') // "[object String]"
Object.prototype.toString.call(true) // "[object Boolean]"
Object.prototype.toString.call(new Boolean(false)) // "[object Boolean]"
Object.prototype.toString.call(null) // "[object Null]"
Object.prototype.toString.call(undefined) // "[object Undefined]"
Object.prototype.toString.call([]) // "[object Array]"
Object.prototype.toString.call({}) // "[object Object]"
Object.prototype.toString.call(Function) // "[object Function]"
Object.prototype.toString.call(Array) // "[object Function]"
Object.prototype.toString.call(Object) // "[object Function]"instanceof 用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上。即判断某个对象是否是某个构造函数的实例。所以主要是用来检测对象和数组,无法准确判断Function 和基本数据类型
1
2
3
4
5
6
7
8
9
10console.log([] instanceof Array); // true
console.log({} instanceof Object); // true
console.log(/\d/ instanceof RegExp); // true
console.log(function(){} instanceof Object); // true
console.log(function(){} instanceof Function);// true
console.log('' instanceof String); // false
console.log(1 instanceof Number); // false
console.log(true instanceof Boolean); // false
模拟实现instanceof
instanceof 用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上。即判断,
实例.__proto__ === 构造函数.prototype或者实例.__proto__.__proto__ === 构造函数.prototype,递归。1
2
3
4
5
6
7
8
9
10
11
12
13function myinstanceof(instance, func){
let left = instance.__proto__;
let right = func.prototype;
while(true){
if(left === null) { // 找到最顶层,原型链的最顶层是null
return false;
}
if(left === right) {
return true;
}
left = left.__proto__
}
}
Object.defineProperty(obj, prop, descriptor)
会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性, 并返回这个对象。默认情况下,使用 Object.defineProperty() 添加的属性值是不可修改的。
- obj 要在其上定义属性的对象。
- prop 要定义或修改的属性的名称。
descriptor 将被定义或修改的属性描述符。属性描述符有两种主要形式:数据描述符和存取描述符。描述符必须是这两种形式之一,不能同时是两者。
数据描述符
- writable
当且仅当该属性的writable为true时,value才能被赋值运算符改变。默认为 false。 value
该属性对应的值。可以是任何有效的 JavaScript 值(数值,对象,函数等)。默认为 undefined。存取描述符
- get
当访问该属性时,该方法会被执行,默认为 undefined。 set
当属性值修改时,触发执行该方法,该方法将接受唯一参数,即该属性新的参数值。默认为 undefined数据描述符和存取描述符均具有以下可选键值
- configurable
当且仅当该属性的 configurable 为 true 时,该属性描述符才能够被改变(也就是可以被重新defineProperty),同时该属性也能从对应的对象上被删除。默认为 false。 - enumerable
当且仅当该属性的enumerable为true时,该属性才能够出现在对象的枚举属性中。默认为 false。
- writable
call,apply,bind区别
用法:
- call方法第一个参数是函数运行时this指向的对象,后面跟多个参数。返回值取决于原始函数的返回值。
- apply方法第一个参数也是函数运行时this指向的对象,后面跟参数数组。返回值取决于原始函数的返回值。
- bind方法返回值是一个新的函数,这个新的函数被调用时,this指向bind的第一个参数。bind方法后面也可以接收多个参数传递给原始函数。
区别:
- 第一个参数都是 要绑定的this指向.
- apply的第二个参数是一个参数数组,call和bind的第二个及之后的参数作为函数实参按顺序传入。
- bind不会立即调用,其他两个会立即调用。
模拟实现call, apply, bind
模拟实现call1
2
3
4
5
6
7
8Function.prototype.call2 = function(context, ...args) {
const ctx = context || window; // 如果没有传参,则指向window
// ctx.func只是一个名字,可以随便取。this是被调用的函数,因为函数调用call方法,call里面的this就指向那个函数。所以ctx.func就是那个函数。
ctx.func = this;
const result = ctx.func(...args); // 调用该方法并传入参数,此时该方法的this指向ctx
delete ctx.func; // 删除该方法,不然会在传入的对象上添加这个方法。
return result; // 返回返回值。
}
模拟实现apply1
2
3
4
5
6
7Function.prototype.apply2 = function(context, arr = []) {
const ctx = context || window;
ctx.func = this;
const result = ctx.func(...arr); // 跟call唯一的区别是参数不一样
delete ctx.func;
return result;
}
模拟实现bind1
2
3
4
5
6
7
8
9Function.prototype.bind2 = function(context, ...args) {
const ctx = context || window;
ctx.func = this;
return function() { // 跟call的区别是不立即执行,而是返回一个函数。
const result = ctx.func(...args);
delete ctx.func;
return result;
}
}
深拷贝,浅拷贝,Object.assign()、ES6的扩展运算符
浅拷贝只是拷贝了指向对象的指针。
深拷贝则是完全拷贝了整个值,创建了一个新的和原对象值一样的对象。
- 浅拷贝 直接赋值
- 深拷贝用_.deepclone、JSON.parse(JSON.stringify(obj))
扩展运算符和Object.assign()都是只复制最外面一层,所以根属性是深拷贝,里面的对象依然是浅拷贝
实现深拷贝
1 | var a = { |
简易版: JSON.parse(JSON.stringify(obj));
- 无法解决循环引用问题,会报错。 比如上面的 a.g = a.
- 无法复制值为undefined的
- 无法复制函数
- 无法复制一些特殊的对象,如 RegExp, Date, Set, Map等
面试版:
- 第一层如果是对象,循环每一个key,判断每一项
- 判断是对象,如果循环引用,返回本身。否则递归调用自身。
- 判断是数组,遍历数组的每一项,如果是对象,递归调用自身,否则直接返回
- 判断是函数,重新生成函数
- 值类型直接复制
- 第一层如果是数组,递归每一个元素。
第一层如果是值类型,直接复制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33function deepClone(obj) {
let newobj;
if (Object.prototype.toString.call(obj) === '[object Object]') { // 先判断目标类型
newobj = {};
for(let key in obj) {
let value = obj[key];
if (Object.prototype.toString.call(value) === '[object Object]') {
if (value === obj) { // 循环引用
newobj[key] = obj;
} else {
newobj[key] = deepClone(value); // 递归本身
}
} else if (Object.prototype.toString.call(value) === '[object Array]') {
newobj[key] = value.map(item => {
return deepClone(item); // 递归数组元素
})
} else if (Object.prototype.toString.call(value) === '[object Function]') {
newobj[key] = function() { return value.call(this, ...arguments) } // 重新构建函数
} else {
newobj[key] = value;
}
}
} else if (Object.prototype.toString.call(obj) === '[object Array]') {
newobj = [];
for (let i = 0; i < obj.length; i++) {
newobj.push(deepClone(obj[i])) // 递归数组的元素
}
} else {
newobj = obj;
}
return newobj;
}
- 第一层如果是对象,循环每一个key,判断每一项
节流(throttle),防抖(debounce)
- 节流:频繁操作的时候,如果超过了设定的时间,就执行一次处理函数。周期性的执行。节流会稀释函数的执行频率。
- 防抖:频繁操作的时候,如果两次的间隔时间超过了设定的时间,就执行一次处理函数,如果时间没到的时候,就把timer清除。只执行最后一次。需要一个定时器。
- 函数防抖是某一段时间内只执行一次,而函数节流是间隔时间执行。
实现节流
1 | function throttle(method, delay) { |
实现防抖
1 | function debounce(method, delay) { |
JS 异步解决方案的发展历程以及优缺点
回调函数
缺点:回调地狱,不能用 try catch 捕获错误,不能 returnPromise
优点:解决了回调地狱的问题
缺点:- 无法取消Promise,一旦新建它就会立即执行,无法中途取消。
- 如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。
- 当处于Pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。
- Promise 真正执行回调的时候,定义 Promise 那部分实际上已经走完了,所以 Promise 的报错堆栈上下文不太友好。
Generator
缺点: 使用复杂,需要配合co库async/await
优点:- 同步的写法
- 可以try catch
- 没有then的链式调用
- 错误堆栈信息友好
方便调试
缺点:
用async/await需要注意的是,如果里面有多个Promise,需要注意他们是否有依赖,没有依赖的话用await Promise.all([…])
map、forEach、for in、for of、Object.keys
- for in 遍历对象的key,因为key排序的问题,for-in语句无法保证遍历顺序。
for (var prop in obj) { ... } - for of ES6引入,用来遍历任何有Iterator接口的数据结构,如数组, Set, Map, String, Arguments等
for (var value of arr) { ... } - forEach 遍历数组,不影响原数组
arr.forEach((value, index, arr) => { ... }) - map 遍历数组,并返回一个新的数组,新数组元素为原来的数组的每个元素调用func的结果,不影响原数组
arr.map((value, index, arr) => { return ... }) - Object.keys也是循环对象的key,返回一个数组
js 跳出循环,break, continue, return
for 循环,for of循环,while循环,for in循环。都是break跳出循环,continue下一次循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27const arr = [0,1,2,3,4,5];
for(let i=0; i<arr.length;i++){
if(i===1) continue;
if(i===4) break;
console.log(arr[i])
}
for(let i of arr){
if(i===1) continue;
if(i===4) break;
console.log(arr[i])
}
let i = 0;
while(i < arr.length){
console.log(arr[i])
i++;
if(i===1) continue;
if(i===4) break;
}
const obj = {a:'a',b:'b',c:'c',d:'d',e:'e'}
for(let key in obj){
if(key==='a') continue;
if(key==='e') break;
console.log(i)
}map, forEach等循环,不能跳出循环,如果想跳出,只能主动抛出一个异常。throw new Error()
return 一般用来作为函数的返回值,不能单独用在循环中。
前端存储方式
cookie
cookie 中主要存储sessionid,过期时间,域名,路径等。会在发送请求的时候自动携带。为了维持服务器的状态。大小只有4k。localStorage
localStorage 通过key-value存储一些值,大小为5兆,会永久存储在客户端。sessionStorage
sessionStorage 跟localStorage相似,会话级别,关闭页面就会消失。IndexDB
前端的非关系型数据库,用于在客户端存储大量的数据.
字符串操作
str.charAt()返回在指定位置的字符str.concat(str2)连接字符串str.indexOf(str2)返回某个指定的字符串值在字符串中首次出现的位置str.lastIndexOf(str2)返回一个指定的字符串在字符串中最后出现的位置,从后向前搜索str.match(regexp)在字符串内找到一个或多个正则表达式的匹配,返回一个数组str.replace(regexp/substr, str2)在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串str.search(regexp/substr)检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串,返回相匹配的子串的起始位置str.split(),将字符串变为数组,以某符号分割。str.slice(start,end)返回一个新的字符串。从 start 开始(包括 start)到 end 结束(不包括 end)。str.substr(start, length)抽取从 start 下标开始的指定数目的字符。str.substring(start, end)返回一个新的字符串, 子串包括 start 处的字符,但不包括 stop 处的字符, 与slice() 和 substr() 方法不同的是,substring() 不接受负的参数。str.toLowerCase()把字符串转换为小写。str.toUpperCase()把字符串转换为大写。
ES6新增字符串操作
str.includes(str)返回布尔值,表示是否找到了参数字符串。str.startsWith(str)返回布尔值,表示参数字符串是否在原字符串的头部。str.endsWith(str)返回布尔值,表示参数字符串是否在原字符串的尾部。str.repeat(n)方法返回一个新字符串,表示将原字符串重复n次。n为0则返回空串str.padStart(n, str),str.padEnd(n, str)字符串补全长度。如果某个字符串不够指定长度,会在头部或尾部补全。trimStart()和trimEnd()与trim()一致,trimStart()消除字符串头部的空格,trimEnd()消除尾部的空格。
如何判断是否是数组?
Array.isArray(arr) // es6提供Object.prototype.toString.call(arr) === "[object Array]"arr instanceof Arrayarr.constructor === Array
一般用1,2方法
数组操作
arr.push(a, b, c...)从后面添加一个或多个元素,返回值为添加完后的数组的长度arr.pop()从后面删除元素,只能是一个,返回值是删除的元素arr.shift()从前面删除元素,只能删除一个 返回值是删除的元素arr.unshift(a, b, c...)从前面添加一个或多个元素, 返回值是添加完后的数组的长度。第一个参数将成为数组的新元素 0,如果还有第二个参数,它将成为新的元素 1arr.slice(start, end)返回索引值start到索引值end的数组,不包含end元素,不改变原数组,如果不传参数,则返回它本身的副本。arr.splice(i, n, item1,...,itemX)从数组中删除从i开始的n个元素,返回被删除的数组,还可以传入其他的值来替换被删除的数组项目arr.join()将数组变为字符串,以传入的参数连接- 易混淆的一个string的方法,
str.split(),将字符串变为数组,以某符号分割 arr.concat(newArr)连接两个数组 返回值为连接后的新数组arr.reverse()将数组反转,返回值是反转后的数组arr.sort()将数组进行排序,返回值是排好的数组。默认将按字母顺序对数组中的元素进行排序,说得更精确点,是按照字符编码的顺序进行排序。
如果传入了比较函数:- 如果 compareFunction(a, b) 小于 0 ,那么 a 会被排列到 b 之前
- 如果 compareFunction(a, b) 等于 0 , a 和 b 的相对位置不变
- 如果 compareFunction(a, b) 大于 0 , b 会被排列到 a 之前
- 总结: a-b 是升序,b-a是降序
arr.forEach((value, index, arr) => { ... })遍历数组, 无return, 不改变原数组arr.map((value, index, arr) => { ... })遍历数组, 返回一个新数组, 不改变原数组arr.filter((value, index, arr) => { ... })过滤数组,返回一个满足要求的数组arr.every((value, index, arr) => { ... })依据判断条件,数组的元素是否全满足,若满足则返回ture。全真则真,一假即假arr.some((value, index, arr) => { ... })依据判断条件,数组的元素是否有一个满足,若有一个满足则返回ture。有真则真,全假才假arr.reduce((total, value, index, arr) = > { ... }, initValue)为数组中的每一个元素依次执行callback函数,并将函数的返回值作为total参数传给下次循环
ES6新增数组操作
Array.from()将对象转为数组:string,arguments, Set, Map, key是数字的对象Array.of()用于将一组值,转换为数组。Array.of(3, 11, 8) // [3,11,8]arr.copyWithin(target, start, end)将指定位置的成员(从start到end,不包含end的成员)复制到其他位置(从target开始)(会覆盖原有成员),然后返回当前数组。- target(必需):从该位置开始替换数据。
- start(可选):从该位置开始读取数据,默认为 0。
end(可选):到该位置前停止读取数据,默认等于数组长度。
[1, 2, 3, 4, 5].copyWithin(0, 3) // [4, 5, 3, 4, 5]用4,5把1,2替换[1, 2, 3, 4, 5].copyWithin(0, 3, 4) // [4, 2, 3, 4, 5]用4把1替换
arr.find((value, index, arr) => { ... })找出第一个符合条件的数组元素,然后返回该元素arr.findIndex((value, index, arr) => { ... })找出第一个符合条件的数组元素,然后返回该元素的位置arr.includes()返回一个布尔值,表示某个数组是否包含给定的值,与字符串的includes方法类似arr.entries(),arr.keys()和arr.values()用于遍历数组。keys()是对键名的遍历、values()是对键值的遍历,entries()是对键值对的遍历。arr.flat()用于将嵌套的数组“拉平”。默认只会“拉平”一层,如果想要“拉平”多层的嵌套数组,可以给flat()方法的参数传入一个整数,表示想要拉平的层数。
[1, 2, [3, 4]].flat() //[1, 2, 3, 4]
[1, 2, [3, [4, 5]]].flat() //[1, 2, 3, [4, 5]]
[1, 2, [3, [4, 5]]].flat(2) //[1, 2, 3, 4, 5]arr.flatMap((value, index, arr) => { ... })先执行map,然后对返回值组成的新数组执行flat()方法。
数组去重
用Set, let newArr = [..new Set(arr)]
如果是对象,用reduce1
2
3
4
5
6
7
8let temArr = [];
const uniqueList = totalList.reduce((prev, next) => {
if (!temArr.includes(next.id)) {
temArr.push(next.id);
prev.push(next);
}
return prev;
}, []);
数组合并
concat, […a, …b]扩展运算符
数组循环中删除元素
1 | for (let i=0; i<arr.length; i++) { |
函数内部 arguments 变量有哪些特性,有哪些属性,如何将它转换为数组
arguments对象是所有(非箭头)函数中都可用的局部变量。可以使用arguments[i]引用函数的参数,也可以修改函数参数。修改的只是函数的形参,并不会影响实参。
arguments.callee指向当前执行的函数。arguments.caller指向调用当前函数的函数。arguments.length指向传递给当前函数的参数数量。
转换为数组:
var arr = [...arguments];Array.prototype.slice.call(arguments);Array.from(arguments)
设计模式
- 工厂:工厂起到的作用就是隐藏了创建实例的复杂度,只需要提供一个接口,简单清晰。
- 单例:保证每次访问得到的都是同一个对象,可以用全局对象存储。
- 适配器:为了解决两个接口不兼容的情况,通过包装一层实现两个接口正常协作。
- 装饰模式:不需要改变已有的接口,作用是给对象添加功能。
- 代理模式:代理是为了控制对对象的访问,不让外部直接访问到对象。代理类可以访问并操作对象,然后暴露相关方法供外部调用。
- 发布订阅(观察者)模式:当对象发生改变时,订阅方都会收到通知。先定义一个对象,这个对象包含on方法和trigger方法,以及一个存储回调函数的list。on的时候往list里面push,trigger的时候再从list中拿出来并执行。
jquery插件开发
其实就是给jquery增加一种新的方法。
一种是类级别的插件开发,即给jQuery添加新的全局函数,相当于给jQuery类本身添加方法。jQuery的全局函数就是属于jQuery命名空间的函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19jQuery.foo = function() {
alert('This is a test.');
};
// 或
jQuery.extend({
foo: function() {
alert('This is a test.');
}
});
// 但是一般我们都加上命名空间去使用
jQuery.myPlugin = {
foo: function() {
alert('This is a test.');
}
};
//调用
jQuery.foo();
$.foo();
$.myPlugin.foo();另一种是对象级别的插件开发,即给jQuery对象添加方法。这就需要把方法添加到jQuery的prototype上。查看jQuery源码可以发现jQuery.fn=jQuery.prototype。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18$.fn.test = function() {
alert('this is test2');
return this; // 为了满足链式调用
}
// 或
$.fn.extends({
test: function() {
alert('this is test2');
return this;
}
})
// 但一般我们为了防止$.fn被其他库污染,都用立即执行函数定义
(function($){
$.fn.test = function(){
alert('this is test2');
return this;
}
}(jQuery));
jquery绑定事件,取消绑定,触发事件
on, off, trigger
前端模块化的发展历程
IIFE
立即执行函数定义模块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15var utilModule = (function() {
var module = {};
var name = 'utilModule';
module.setName = function(value) {
name = value;
};
module.getName = function() {
return name;
};
return module;
})();
utilModule.getName() // "utilModule"
utilModule.setName('test')
utilModule.getName() // "test"CommonJS
Nodejs的模块规范, 用module.exports定义当前模块对外输出的接口(不推荐直接用exports),用require加载模块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// module.js
var name = 'testModule';
var setName = function(value) {
name = value;
}
var getName = function() {
return name;
}
module.exports = {
setName,
getName
}
// main.js
var testModule = require('./module.js')
console.log(testModule.getName()); // testModule
testModule.setName('test');
console.log(testModule.getName()); // testAMD
require.js遵循了这个规范。通过define方法去定义模块,通过require方法去加载模块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// a.js
// 定义独立的模块
define({
test: function() { console.log('this is test1'); }
})
// b.js
// 另一种定义独立模块的方式
define(function() {
return {
test: function() {console.log('this is test2'); }
}
})
//c.js
// 定义非独立的模块(这个模块依赖其他模块)
define(['./a', './b'], function(a, b) {
return {
test: function() {
a.test();
b.test();
}
}
})
// main.js
require(['./c'], function(c) {
c.test();
})
// index.html
<script src="require.js"></script>
<script src="main.js"></script>
// 控制台
this is test1
this is test2CMD
seajs遵循了这个规范。通过define方法去定义模块,通过seajs.use去加载模块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39// a.js
define(function(require, exports, module) {
var test = function() {
console.log('this is test1');
}
module.exports = { test }
});
// b.js
define(function(require, exports, module) {
var test = function() {
console.log('this is test2');
}
module.exports = { test }
});
//c.js
define(function(require, exports, module) {
var a = require('./a');
var b = require('./b');
var test = function() {
a.test();
b.test();
}
module.exports = { test }
});
// main.js
seajs.use('./c', function(c) {
c.test();
});
// index.html
<script src="sea.js"></script>
<script src="main.js"></script>
// 控制台
this is test1
this is test2ES6 module
1
2
3
4export
export default
import
import * as ...UMD
UMD是同时支持AMD和CommonJS的规范。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19(function (root, factory) {
if (typeof define === "function" && define.amd) {
// 如果环境中有define函数,并且define函数具备amd属性,则可以判断当前环境满足AMD规范
define(["test"], factory());
} else if (
typeof exports === "object" &&
typeof module.exports === "object"
) {
// 是commonjs模块规范,nodejs环境
module.exports = factory();
} else {
// 浏览器全局变量(root 即 window)
root.umdModule = factory();
}
})(this, function () {
return {
name: "我是一个umd模块",
};
});
AMD 和 CMD 的区别
- 对于依赖的模块,AMD 是提前加载,CMD 是延迟加载。
- 从规范上,CMD更贴近CommonJS的异步模块化方案
ES6 模块和 CommonJS 模块的区别
- commonJS 模块输出的是一个值的拷贝,ES6模块输出的是值的引用
- commonJS模块一旦输出一个值,模块内部的变化就影响不到这个值。
- ES6模块如果使用import从一个模块加载变量,那些变量不会被缓存,而是成为一个指向被加载模块的引用,原始值变了,import加载的值也会跟着变。
- commonJS 模块是运行时加载,ES6 模块是静态编译时加载,所有可以用于tree shaking
- 运行时加载: CommonJS 模块就是对象;即在输入时是先加载整个模块,生成一个对象,然后再从这个对象上面读取方法,这种加载称为“运行时加载”。
- 编译时加载: ES6 模块不是对象,而是通过 export 命令显式指定输出的代码,import时采用静态命令的形式。即在import时可以指定加载某个输出值,而不是加载整个模块,这种加载称为“编译时加载”。
- CommonJS 模块的require()是同步加载模块,ES6 模块的import命令是异步加载
CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
module.exports和exports的区别
- exports是module.exports的引用, 即
var exports=module.exports - 初始时这两个变量是指向同一个空对象
- 当执行完毕时只有module.exports会被返回。
所以
- 当你想导出的东西可以在空对象上直接扩展就可以的时候,用exports当然省时省力
- 当你想导出的东西要完全覆盖掉空对象的时候,只能用module.exports了
- 当你分不清楚的时候请用module.exports